Resume RAG Chatbot
Deployed a web app for users to chat about a resume. The app leverages a user-friendly web interface for seamless interaction and real-time responses.
Integrated Facebook AI Similarity Search (FAISS) for efficient and high-speed similarity search over resume embeddings. This allows the chatbot to quickly retrieve the most relevant sections of the resume based on user queries.
Utilized a Transformer-based model (e.g., T5 or BART) to generate coherent and contextually accurate responses. The model is fine-tuned to provide specific answers from the resume content, enhancing the relevance and accuracy of the responses.
Fine-tuned generation parameters, iterated through model selection, implemented caching, and employed selection criteria for text chunks to balance memory usage with meaningful responses.


Which-Parent
Developed an AI-powered facial comparison tool to quantitatively determine parent-child resemblance
Implemented a user-friendly interface using Streamlit, demonstrating proficiency in creating intuitive web applications
Leveraged transfer learning by fine-tuning a pre-trained ResNet model for facial feature extraction
Robust image processing pipeline for consistent input handling across various image formats and qualities
Designed a custom similarity scoring algorithm using cosine similarity of facial embeddings
Optimized model inference for real-time processing, ensuring quick results even on consumer-grade hardware
Washington Hiker’s Guide

Developed a custom web scraper to extract data on over 3000 hiking trails from the Washington Trails Association guide
Created a comprehensive set of trail features, including difficulty metrics, geographical attributes, and NMF topic modeling on trail descriptions
Designed and implemented a machine learning-based recommendation algorithm to suggest similar trails based on user preferences and historical data
Deployed a user-friendly web interface using Streamlit, enabling intuitive filtering and exploration of hiking traills
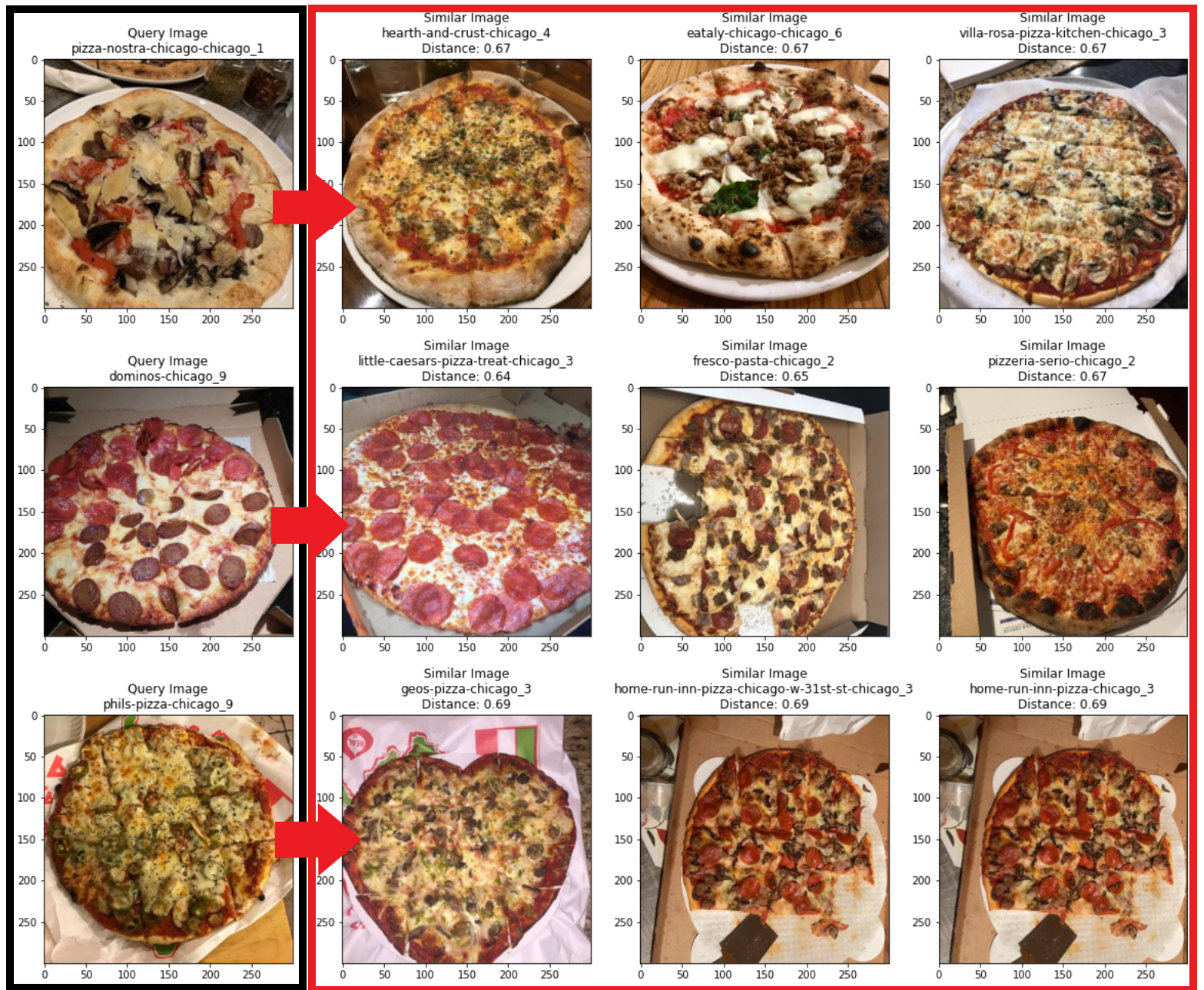
Developed a robust web scraper to extract reviews and images from nearly 1000 Chicagoland pizza restaurants on Yelp
Implemented data cleaning and preprocessing pipelines to handle text and image data
Trained a custom Autoencoder convolutional neural network for efficient image encoding
Fine-tuned a pre-trained ResNet50 model for pizza-specific feature extraction, demonstrating transfer learning skills
Applied Non-negative Matrix Factorization (NMF) to extract key topics from user reviews, enabling content-based filtering
Successfully deployed the recommendation engine, making it accessible to users seeking to discover new pizzas
Computer Vision for Pizza Similarity
Developed an intuitive Streamlit web app that captures user preferences and generates personalized coffee recommendations, enhancing the coffee discovery experience for enthusiasts
Developed a web scraping pipeline to extract and clean text and quantitative data from 6000 coffee reviews on coffeereview.com
Applied advanced NLP techniques including Topic Modeling and Non-negative Matrix Factorization (NMF) to uncover latent themes in coffee reviews
Utilized TF-IDF (Term Frequency-Inverse Document Frequency) to identify key descriptors and differentiate between coffee profiles
Developed a machine learning model to predict coffee scores based on extracted features and user preferences
Conducted exploratory data analysis to uncover trends and patterns in coffee preferences and ratings
A Discovery Platform For Coffee Lovers

Data used was a million ticket sample of the ProPublica dataset on Chicago tickets, taken as a proof of concept
Established an MVP to be finetuned and deployed to either help identify which tickets ultimately help generate revenue or which tickets may require support in receiving payment
Predicted whether a parking ticket written in Chicago for a passenger vehicle will be paid or unpaid by utilizing classification algorithms and engineering features to optimize AUC-score (logistic, random forest, gradient boosted trees)
Improved separation between classes by handling class imbalance, ensembling, and gradient boosting
Chicago Parking Tickets - Predicting Payment status

Player statistics scraped from BaseballReference.com from the careers of pitchers with at least one appearance in season top ten saves list after 1985
Implemented LASSO regularization and linear regression to predict saves for closers in MLB based on past performance
Identified statistics and attributes that contribute most to future performance fell into two categories of dominance and opportunity provided
